
背景介绍
随着自然语言处理(NLP: Natural Language Processing)技术[1]的突飞猛进,以及自动语音识别技术(Automatic Speech Recognition)[2]和语音合成(Speech Synthesis)[3]技术的日渐成熟,智能语音机器人在近三年里迎来了一个爆发期。NLP技术作为语音机器人Pipeline中最重要的部分,在整个对话系统中承担着相当于大脑的作用,也是整个AI最有难度的子领域之一。在我司的许多涉及语音对话的业务场景中,NLP技术一直为语音机器人的多轮对话场景提供着坚实的技术支持。今天我们主要介绍NLP技术在智能语音机器人领域的研究现状和发展趋势,以及在我司的一些探索实践。
在我司的应用场景中,智能对话机器人主要服务于任务导向型的语音对话需求。借助语音机器人的对话,我们获取到用户的反馈,对用户的话语进行理解并作出恰当的回复,这实际上是一种序列决策过程,来满足用户需求或实现对话预设的其它目标。机器人需要在不断的对话过程中通过更新自身对话状态来对下一步动作作出最优选择,进而完成任务。一个完整的语音机器人主要可以分为如下(图1)几个模块[4]。
1. 自动语音识别模块[1]:是一种将人的语音转换为文本的技术。
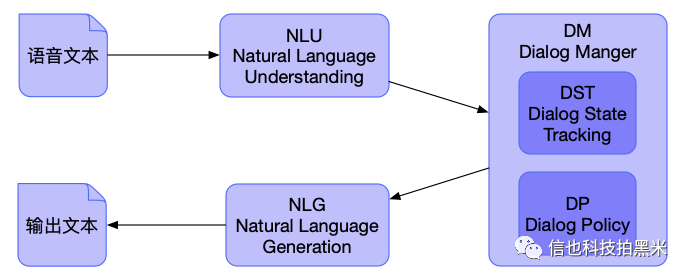
2. 自然语言处理模块[3]:对语音转成的文本进行理解并做出对应输出。包括自然语言理解(Natural Language Understanding,NLU)和自然语言生成(Natural Language Generation,NLG)两部分。
3. 对话管理模块(Dialog Manger,DM)模块:根据对话历史维护当前对话状态,并对当前对话状态输出下一步动作。包括对话状态跟踪(Dialog State Tracking,DST)和对话策略(Dialog Policy,DP)两个子模块。
4. 语音合成模块[2]:一种将文本转化成语音的技术。
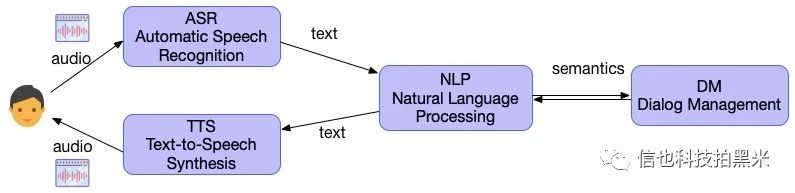

除去独立性较强且和文本处理关系较弱的ASR和TTS模块,语音机器人中的文本处理相关流程又可分为两部分:一类是被工业界广泛应用的Pipeline系统[4, 5],这种模块化的结果会将语音机器人文本处理部分(如图1所示)细分成多个模块,每个模块间即保持自身的原子性,又承担自身承上启下的数据流式处理使命。Pipeline系统的好处是使得整个系统具有很强的可解释性,且工程上相对独立,因而容易在工业界落地,它的缺点是整个流程较长,工程量巨大且联调繁琐,适应不同场景的可移植性较低。文本处理流程的另一类实现是学术界研究比较热门的端到端系统[6],又可以分为监督和无监督两种,其中无监督的对话系统是备受青睐的一个方向(因为有标注数据很难获取,而无标签数据却很容易得到)。端到端系统具有更好的灵活性和可扩展性,但对数据质量和数量要求很高,效果的稳定性也较难控制,目前仍处在探索阶段,还未被工业界广泛应用。
模型介绍
下面我们分两部分,分别介绍Pipeline系统和端到端系统的模型结构。
Pipeline系统
Pipeline系统的语音机器人,在文本处理部分主要采取流程式处理方式,即用机器学习(包括深度学习方法)通过分析海量人工数据以及依靠专家总结归纳,梳理出一套符合对话业务的(基于流程图的)对话系统。在多轮对话的场景流程中,词法分析、特征提取、分类、聚类以及CNN/RNN/Transformer等深度学习算法扮演着重要角色。我们通过机器学习算法控制流程节点的走向,用数据挖掘算法在不同节点挖掘出符合业务场景的优秀话术。
在语音机器人的处理流程中,文本数据来源于ASR模块的转译输出,其数据质量受到ASR转译准确率直接影响,因此我们需要对拿到的语音文本数据做数据清洗(主要是文本纠错),可采用基于统计的方法,基于深度学习的方法(如BERT纠错)等。然后,需要对清洗后的数据进行特征提取。
1.特征抽取
在NLP领域提到特征提取,我们肯定会想到词向量(Word Embedding),特征抽取的目的是为了构建富含信息且不冗余的特征值[7],包括特征构造和特征选择两个部分。在Pipeline系统中特征抽取是为了提取到对话数据中的关键信息,方便后续模型学习。那么什么是词向量呢?
我们知道苹果属于水果的一种,但是如何让机器在水果,蔬菜,谷物……等等多个类别中准确判断出哪一类呢?利用机器学习的思想,我们知道这是一个分类问题,输入数据是(x,y)对,这里x表示苹果,y表示水果,然后我们需要构建一个f(x)->y的映射,让机器通过这个映射学习到x和y之间的关联关系。但是机器只接受数值输入,我们的数据对是符号形式的自然语言(如中文等),因此需要把这种自然语言向量化成数值形式,简单来说,针对词的向量化表示我们称之为词向量。
同样的,所谓句向量就是在数学空间用数值向量化的去表示一个句子。
句向量模型是在词向量的基础上再次进行降维,在更低维度 的连续空间上去表征信息,在我司业务场景中,特征信息主要来源于对话信息,因此如何做好句向量模型是特征抽取的关键步骤。下面我们介绍在我司业务上用到的两种句向量模型。
1)SIF句向量表示
本方法有别于一般的句向量生成方法,采用的是无监督的方式,避免了神经网络模型对标注数据过度依赖的影响,因此更有利于在工业界落地。不同于工业界常用的对句子中词向量直接简单平均的做法,SIF(smooth inverse frequency,平滑逆词频)[8]句向量会对每个词向量赋予不同的权重(Weight),然后每一个词向量分别减去它们在第一个主向量(所有词向量构成的矩阵)上的投影。这样做会删除掉句子中词向量间的共性部分,保留每个词向量的独立特征,从而保证句子向量之间的独立性,提高句子鲁棒性。

其中,a为常数,p(w)为词频。
2)基于Quick Thought句向量的对话表示
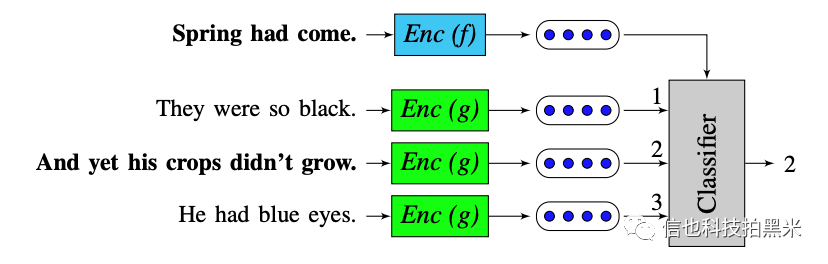
Quick Thought(QT)模型[9]网络如图3所示,模型结构很简单,通过将模型对下一句的预测问题重构为分类问题来达到学习句子表示的目的。在数据预处理时,通过将真实的下句作为正样本(Positive samples),随机选取不在上下文集合中的句子作为负样本(Negative samples),构建输入数据对,然后将数据输入编码器(Encoder)进行编码,最后将输出联合自监督标签(Labels)输入分类器进行训练。我们通过复现QT模型在句子表示上的效果,提出在多轮对话上做对话信息多轮表示的设想,通过对多轮信息建模,模型能够学习到不止当前句子的信息。通过对对话中已发生的所有上下文信息的准确表征,可以避免单轮信息对模型学习带来的不确定性,提高模型效果。
2.意图识别
意图识别是语音对话系统NLU模块中的核心组分,在语音识别的多轮对话系统中,意图识别的作用是去理解用户说了啥,怎么说的,并借助上下文的语义语境从用户的话术中抽象出基础语义定义,然后根据识别到的基础语义定义选择语音机器人后续流程。意图识别的准确率对对话后续流程影响较大,并最终影响到整通对话的质量甚至业务指标。因此提高意图识别准确率是语音机器人搭建的重要环节。
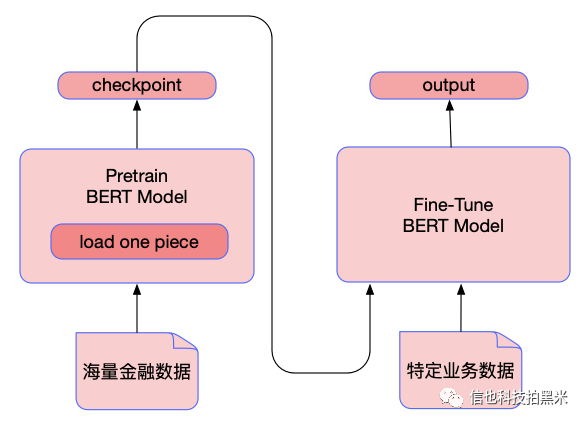
我们的意图识别模型采取BERT预训练+fine-tune的结构,并在loss上做了一些小trick[10]。对NLP领域有所了解的读者一定都知道,BERT(Bidirectional Encoder Representations from Transformers)[11]是在2018年提出来的,其网络架构来源于《Attention is all you need》[12]中提出的Transformer结构,出道即大火,在NLP领域的11个下游任务中取得了SOTA效果。
我们首先利用ASR转译后的人工文本数据对BERT做通用预训练,希望可以弱化ASR转译对后续模型训练带来的负面影响,同时强化模型对我们金融业务的先验知识。实验结果表明,BERT的模型在未对数据做过多处理的条件下,轻松达到了已有模型水平。
3.数据挖掘
在构建语音机器人的过程中,数据挖掘可能不是必须的部分。但是为了完成业务的任务,提高业务的指标,形成语音机器人持续优化的闭环,数据挖掘却是必不可少的一环。如何让机器的表现更接近人,让机器的应答无限接近优秀经办的水平,我们需要挖掘出机器应答和人工应答在业务指标上的gap,分析二者的差异,并从人工数据中挖掘优秀话术和流程方法,将优秀的人工应答套路落地到语音机器人中,优化语音机器人业务能力。
在已获得人工数据特征工程后,通过不断优化聚类算法,梳理人工数据整通对话逻辑和优秀话术(如图5)。整个过程可分为两个部分:一、业务专家通过经验知识为语音机器人构建基础业务流程框架;二、利用已提取句子及多轮对话表示对人工数据按照分支、通为单位分别做横向和纵向分析,按照占比粗细梳理出最贴合真实数据的场景流程图,按照业务最终指标筛选优秀话术作为机器人应答。这两个部分构成了一个优化的闭环,二者相辅相成。

流程图构建好后,当新的外部响应到达时,如何从一个分支节点走向另一个分支节点,需由上一小节介绍的意图识别来决定。当走到某一分支流程时,机器作何应对,是我们话术挖掘的另一目标。意图识别准确率的高低将直接影响流程走向的正确与否。
端到端系统
端到端语音机器人系统是一个偏研究的项目,整个系统由一个文本到文本的生成式模型构成。这里,我们主要尝试了GPT系列的模型。GPT[13]/GPT2[14]网络架构也是来自《Attention is all you need》[12]中提出的Transformer结构,和BERT使用Transformer的Encoder不同,GPT/GPT2的模型结构用的是Transformer的Decoder端。因为其参数规模庞大,效果惊人而广受重视。是继BERT之后又一个将NLP通用模型做到极致的存在,用海量数据的无监督预训练去做有监督的任务,并取得了比以往所有模型更好的效果和泛化性能。
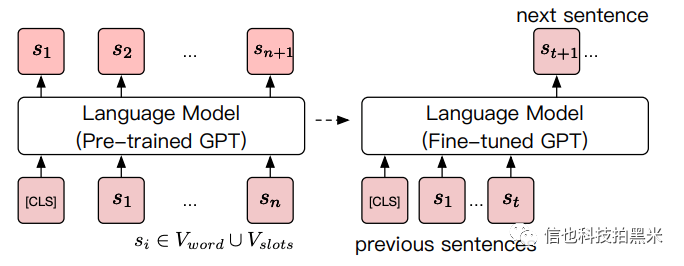
我们首先对原始数据进行实体抽取,将抽取后的实体用预定义好的槽位进行替换,部分槽位如表1所示。将预处理完数据喂入生成式模型训练充分,在模型生成完整应答后进行槽位填充(Slot Filling)。
表1 生成式模型中的部分实体槽位
| 实体 | 槽位 |
| 姓名 | NAME |
| 金额 | MONEY |
| 电话号码 | PHONE |
| 工号 | NUMBER |
| 逾期天数 | OVERDUEDAY |
| 机构 | COMPANY |
实验结果
为了验证模型效果,我们选取了Pipeline系统的线上数据和端到端系统的线下测试数据进行对比。


图中的Customer是在模拟用户输入,Robot是模型输出。可以发现端到端系统槽位预测较准确,比Pipeline方法更加逼近真人,但是在部分逻辑上可能会表现的过于发散,甚至出现逻辑错误的情况。比如图8中“看到您这边昨天下午注册了账号。”这句话是由机器自由生成,缺乏事实依据。相比之下,Pipeline方法因为需要配置话术,灵活性较低,但是逻辑清晰,在意图识别准确的前提下不会答非所问。
小结
本文介绍了语音机器人系统的背景知识、工作原理,以及落地实现做了简单但完整的介绍。基于本人在学术界和工业界的经验,总结了语音机器人的基本结构、落地方法和值得探索的方向,并特别对端到端系统落地的可行性和难点做了初步剖析。
Pipeline系统目前仍是语音机器人的主流方法。由于Pipeline的准确率和效果有连乘的效应,因此提高意图识别准确率,高效的对话管理,以及提高语音识别准确率和语音合成的效果,都决定了语音机器人的最终效果。此外,如何形成一套快速且系统的话术挖掘方法,是迭代提高系统表现的关健。
对端到端系统来说,灵活性和高可扩展性是有它天然的优势,但目前暴露出来的短板也是显而易见的,端到端系统在工业界能完全落地,还需要克服不少现实困难。
本文来自信也科技拍黑米,经授权后发布,本文观点不代表信也智慧金融研究院立场,转载请联系原作者。